Genome sequencing data processing pipelines
BioTech
Genome Sequencing
Python
R
Signal Processing
Developed upstream and downstream pipelines to process amplicon sequencing data
![]()
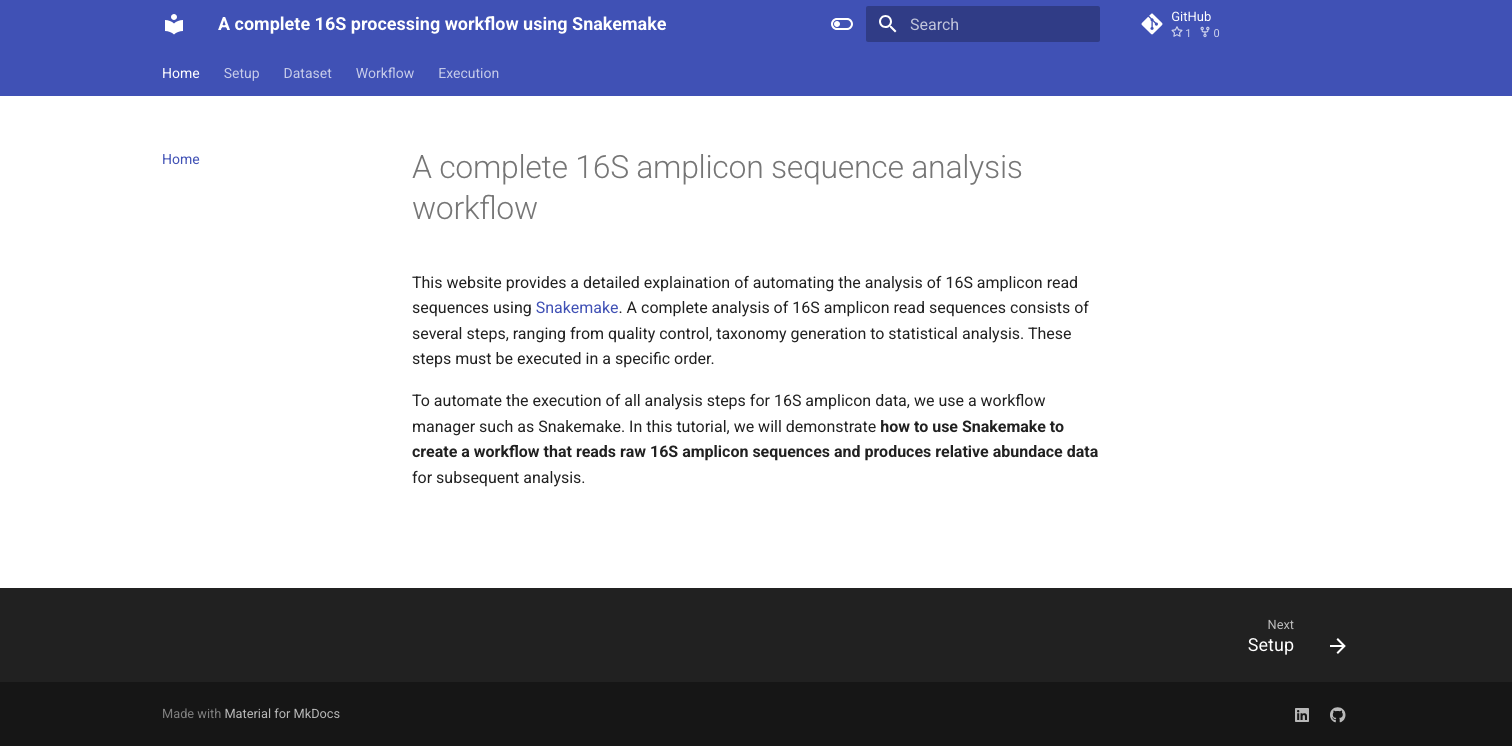
Project overview
This project goal was to establish genome sequencing data processing pipelines to process raw sequencing reads (i.e., FASTQ reads) into microbacterial compositional data. It was a part of a larger project aiming at building a machine learning classifier for colorectal cancer using fecal sample.
Key Features
- End-to-End Automation: Fully automated processing from raw sequencing data to analytical results
- Reproducible Workflows: Pipeline built with Snakemake for reproducible bioinformatics analysis
- Comprehensive Analysis: Produces taxonomic profiles and microbial composition data
- Integration Ready: Output formatted for downstream machine learning applications
- Machine Learning Modeling: Microbial compositional data analyzed using LASSO model to predict colorectal cancer.
⚡ Key Contributions
Developed a fully automated upstream pipeline and downstream pipeline featuring
- Automated quality control and adapter trimming
- Taxonomic classification using QIIME2
- Generation of microbial abundance profiles
- Exploratory analysis of microbial abundance profiles
- Building of a LASSO model for colorectal cancer detection
Skills Applied
Python, R, Signal Processing
Tool/Libraries Used
pandas,matplotlib,ggplot2,qiime2,snakemake