Pandas is a Python API for processing data in a easy and efficient way. This post offers an introduction to this amazing API , especially for beginners.
The post starts with installation instructions of the API and then introduces its functionality with the help of examples.
Installation
There are two options to install the Pandas API on your system. The first option is to install it through Anaconda Distribution which comes with all essential Python packages. While the second option is to install Python on the system and then install Pandas package using the following command.
pip install pandasIntroduction
Now we will explore the API basics. Basically, we will cover the following topics which I think will be good enough to start using Pandas API.- Pandas DataFrame and Series objects
- Reading data CSV files and accessing basic information
- Querying data using loc() and iloc() function
- Handling missing data
- Adding, deleting columns or rows
Pandas DataFrame and Series objects
Pandas’ Series is a one-dimensional array representation of values. we can understand it as an attribute in a dataset. For instance, consider a dataset with three attributes sid (student-id), name, and marks. Now, each of these attributes in pandas is represented as a Series object.
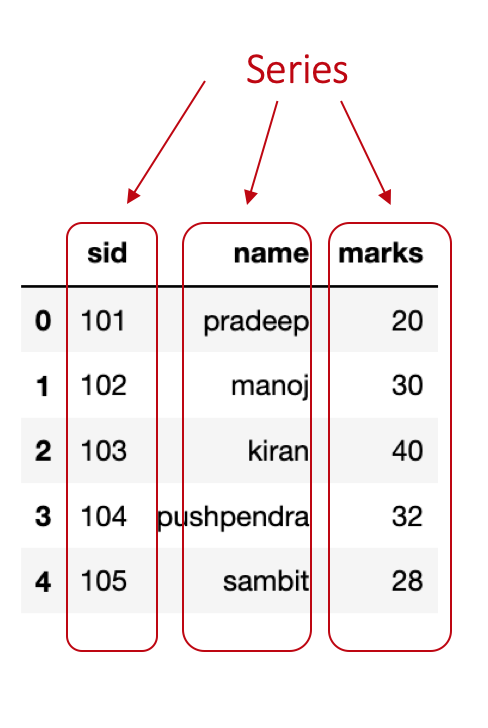
Let’s write a program to create these three Series objects sid, name, and marks.
import pandas as pd
# Creating Series using list
id = pd.Series([101,102,103,104,105])
name = pd.Series(['pradeep','manoj','kiran','pushpendra','sambit']
marks = pd.Series([20,30,40,32,28])</code></pre>The first line import pandas as pd imports the pandas package in wer program. Next, three lines create three Series objects with a given list.
Pandas’ DataFrame object is a two-dimensional data structure where each attribute is a Series object. we can create a DataFrame using a dictionary of key:value pair where the key represents attribute name and the value represents the values of that attribute.
Let’s create a dataframe using the Series objects we created in the above program.df = pd.DataFrame({'sid':id,'name':name,'marks':marks})Reading data CSV files and accessing basic information
Pandas have a function read__csv() to read CSV format data files. This function comes with multiple useful options which we will learn in this section. The data file used in this tutorial can be downloaded from the link. The name of the downloaded data file is iris_csv.csv.
Open and read a CSV data file
import pandas as pd
df=pd.read_csv('iris_csv.csv')
df.head()
df=pd.read_csv(‘iris_csv.csv’) opens and reads the specified CSV file (here we can specify the name of wer data file). The third line df.head() shows first five records (we can specify the number of records) from wer data file.
Assign/Rename column names
In case, if wer data file does not have column names or we want to assign a different column name then we can use the names option of read_csv() function.
Example:
import pandas as pd
df = pd.read_csv('iris_csv.csv',names=['sep-len','sep-wid','pet-len','pet-wid','class'])Reading data file with different seperator
Sometimes the data files have columns seperated by other characters (e.g. spaces, colon). In such cases, in order to read the CSV file we need to specify the sep option in the read_csv() function.
# reading file having data seperated by :
df = pd.read_csv('data_file',sep=':')Skipping rows while reading data
In case, if wer data file does not have data records from the first line (let’s say it contains some summary or description and data records begins from line 4), we can skip those lines by specifying skip rows option.
df = pd.read_csv('data_file',skiprows=3)Accessing sizes of data
we can check the size of wer data set (e.g. number of rows, number of columns) using shape property of the DataFrame.
import pandas as pd
df = pd.read_csv('iris_csv.csv')
print(df.shape)
# output
# (150, 5)Here, 150 is the number of rows and 5 is number of columns.
Checking data types of columns
To check the data types of columns in the data file, we can use <a href=““https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dtypes.html”“>dtypes property.
import pandas as pd
df = pd.read_csv('iris_csv.csv')
df.dtypes</code></pre>Output:
sep-len float64
sep-wid float64
pet-len float64
pet-wid float64
class object
dtype: objectAs the data processing modules requires wer data to be in numeric data types (e.g. int, float) it is best practice to check the data types before processing it.
Basic stats of data
If we want to learn about our data in more depth, we can use describe() function. This function provides information about count, minimum, maximum, mean, standard deviation, quartiles for each column. An example is given below.
import pandas as pd
df = pd.read_csv('iris_csv.csv',skiprows=1,names=['sep-len','sep-wid','pet-len','pet-wid','class'])
df.describe()</code></pre>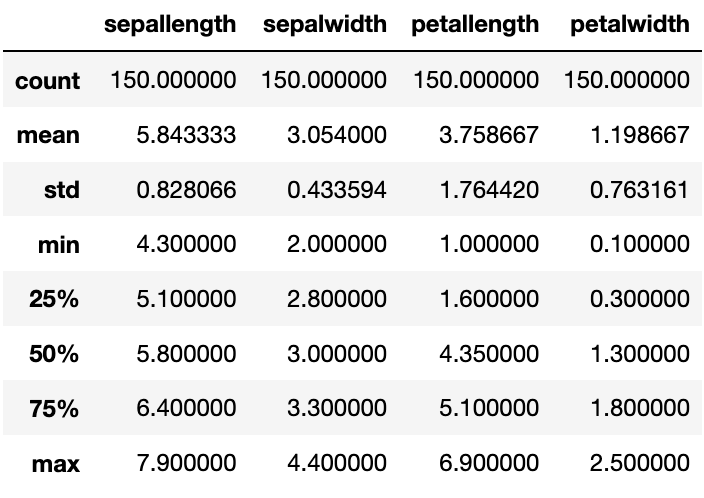
Querying data using loc() and iloc() function
Pandas offers two different functions (there is one more ix() which is actually deprecated) for accessing data from the dataframe- .loc() and .iloc(). In these functions, we specify the labels or positions of rows and columns to access data. However, if we do not specify columns selector then by default all columns are accessed.
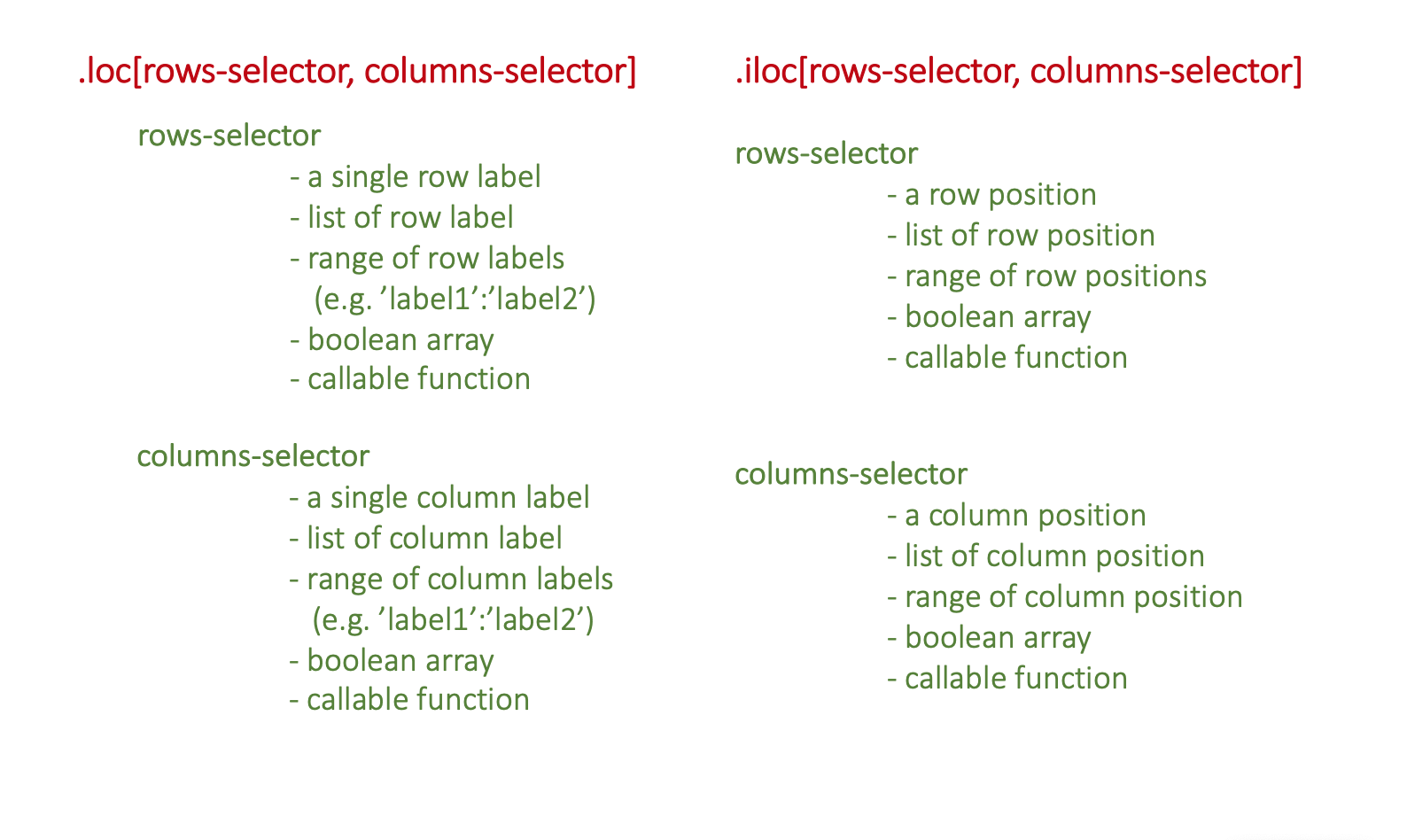
: operator used for slicing purpose. It works differently in case of label and position. When applied with labels (start:end), it include end element in the result. However, in case of positions (start:end), it does not include end in the result.
Let’s understand the difference between labels and positions. In the following code, we are creating a simple dataframe with two columns sid and name.
import pandas as pd
df = pd.DataFrame({'sid':[101,102,103,104,105],'name':['pradeep','manoj','kiran','pushpendra','sambit']})
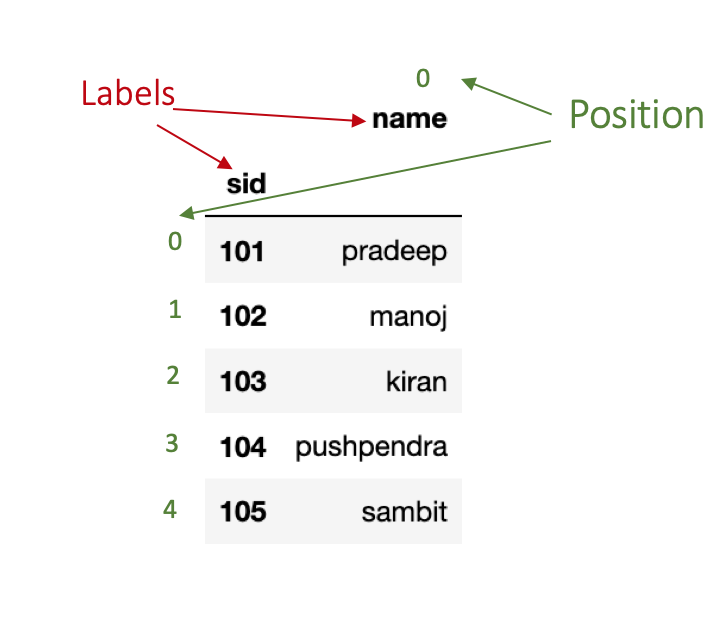
df.head()As shown in the figure below, the row labels are (0,1,2,3,4) and column labels are (sid, name).
The position for rows and columns begins with 0 that means the first row has position 0, second row has position 1 and so on. 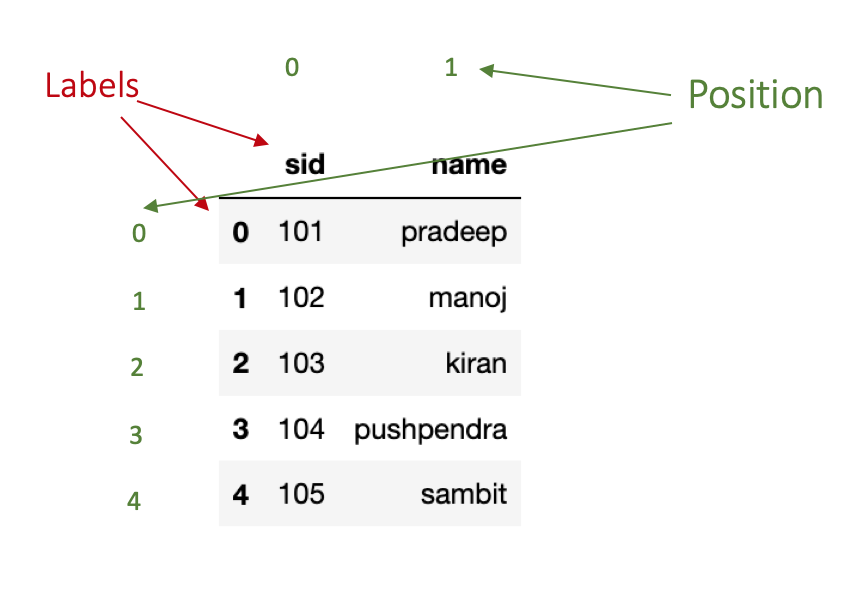
In the above example, the rows position and labels are same. To make the difference clear, let’s try to change the index of our dataframe and then see it.
we can change the index of dataframe using set_index() function. In the following example, we are setting the first column sid as the index of our dataset. This function create a copy of dataframe, apply changes it it and then return the updated copy. In order to make changes to dataframe inplace=True parameter needs to be passed.
df.set_index('sid',inplace=True)
df.head()As we can see in the figure below, rows’ indices are (101,102,103,104,105) whereas rows’ positions are the same as previous.
Some Examples
The following figure shows some examples for accessing data with label and position-based selections.
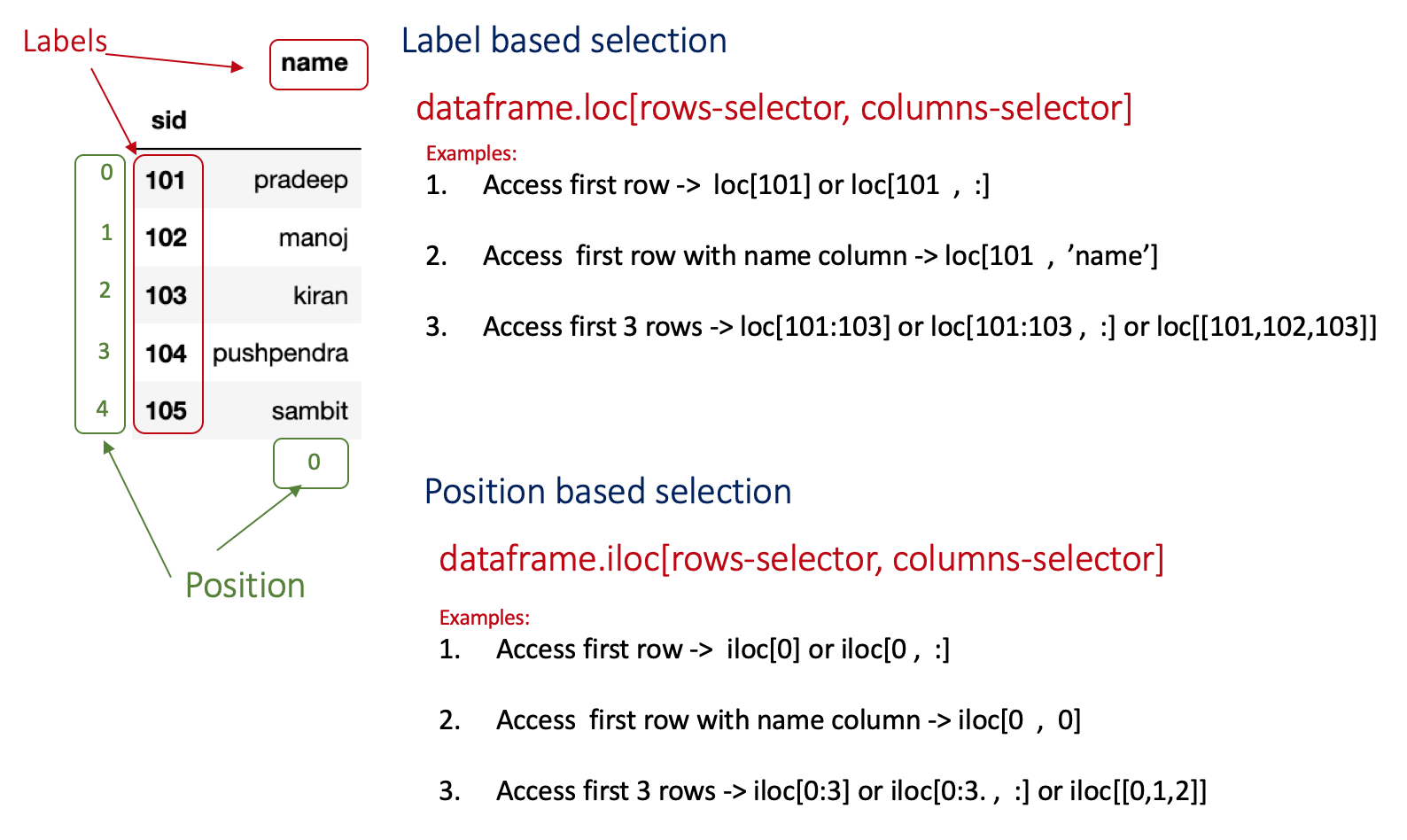
To access a particular row, we need to specify its label or position in the row-selector (for example, we have to specify label 0 to access first row). In case, if we want to access multiple rows, we need to specify their corresponding labels or positions in a list or we can use : operator for slicing (for example, row selector for accessing first three rows can be [0,1,2] or 0:3).
# import pandas package
import pandas as pd
# create the dataframe
df = pd.DataFrame({'sid':[101,102,103,104,105],'name':['pradeep','manoj','kiran','pushpendra','sambit']})
# set sid as index
df.set_index('sid',inplace=True)
# Access first row
df.loc[101] # lable-based
df.iloc[0] # Position-based
# Access first three rows
df.loc[101:103] # label-based
df.iloc[0:3] # position-basedCondition-based data access
Function loc() and iloc() both support condition-based data access using boolean array. Let’s say we want to access the first row. To do that we need to specify a boolean array for rows selection. This array will contain a boolean value for each row and only one True value.
import pandas as pd
df = pd.DataFrame({'sid':[101,102,103,104,105],'name':['pradeep','manoj','kiran','pushpendra','sambit']})
df.loc[[True,False,False,False,False],[True,True]]
#Output
# sid name
#0 101 pradeep
In the above example, we spcified a boolean array for rows selection and another for columns selection. In the first array, True is specified at the first index (which corresponds to the first row). The second array contains all True(which corresponds to all columns). Hence, we get the values from the first row and both columns.
Handling missing data
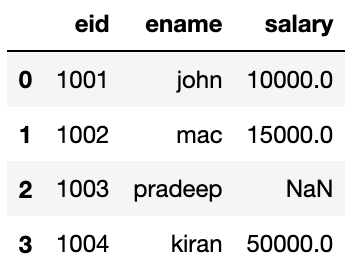
Pandas offers a great support to handle missing values. If the dataset has some values missing, Pandas automatically marks them as NaN values. To demonstrate it, I have prepared a CSV file with three columns- eid, name, salary.

In this file, I intentionally kept the salary field for the third record empty for the following exercises on the missing values.
Now let’s read this file using pandas.
df=pd.read_csv('emp.csv')
df.head()Output:
We can handle missing values in two ways: delete or replace. The following sections discusses these both ways.
Deleting missing values
We can use the dropna() function to delete missing records.
In this function, we need to specify axis=0 if we want to delete the row/rows having NaN and for deleting column/columns having NaN specify axis=1.
df=pd.read_csv('emp.csv')
#delete row
df1 = df.dropna(axis=0)
df1.head()
#delete column
df1 = df.dropna(axis=1)
df1.head()</code></pre>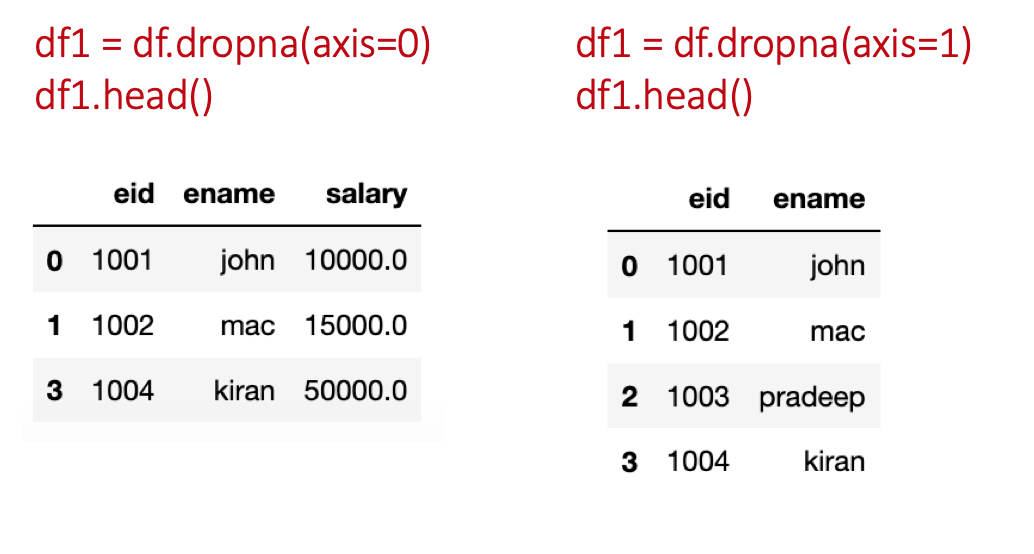
To change the original dataframe, specify inplace=True in the dropna() function.
Filling missing values
Function fillna is useful in filling missing values in the dataframe.
df=pd.read_csv('emp.csv')
#fill with 0
df1 = df.fillna(0)
df1.head()
#fill using forward fill method
df2 = df.fillna(method='ffill')
df2.head()
# fill using backward fill method
df3 = df.fillna(method='bfill')
df3.head()
# fill using mean value of column
df4 = df.fillna(df['salary'].mean())
df4.head()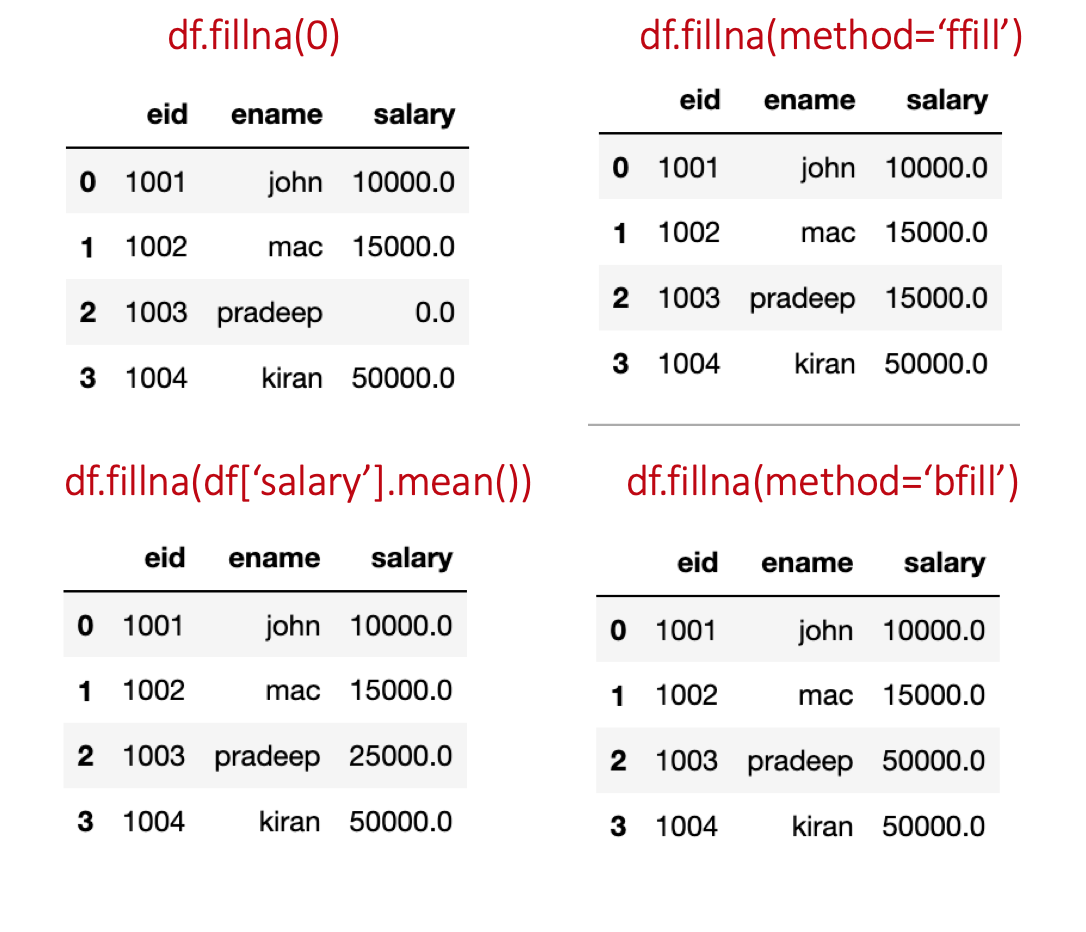
ffill replaces NaN with the previous value in the same column. While, bfill replaces NaN with the next value in the same column (order of values top to bottom).
Add or delete row/column
This section will show we how to add a new row or column to an already existing dataframe.
Adding row/column
We can simply add a row using append() or loc()/iloc() function. We can use key:value pair in the append function, where the key is the attribute name and the value represents the value we want to add. Pandas automatically puts NaN if some attributes values are not provided.
sid as 106 and name as ‘gaurav’.
import pandas as pd
df = pd.DataFrame({'sid':[101,102,103,104,105],'name':['pradeep','manoj','kiran','pushpendra','sambit']})
# using the append function
df = df.append(append({'sid':106,'name':'gaurav'},ignore_index=True)
print(df)
# Adding a column
df['marks'] = [20,30,40,32,28,50]The same record can also be added using df.loc[5]=[106,‘gaurav’].
Deleting row/column
To delete some columns or rows, the drop function can be used. In this function, we need to specify the label of row or column we want to delete. In case, it is a column then we also need to pass a parameter axis=1.
drop function.
import pandas as pd
df = pd.DataFrame({'sid':[101,102,103,104,105],'name':['pradeep','manoj','kiran','pushpendra','sambit']})
# delete sid column
df.drop('sid',axis=1)