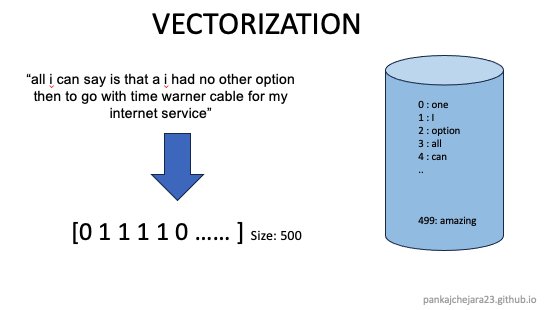
Size: torch.Size([100, 7356])
Batch example: {'x_data': tensor([[1., 1., 1., ..., 0., 0., 0.],
[1., 0., 1., ..., 0., 0., 0.],
[1., 1., 1., ..., 0., 0., 0.],
...,
[1., 1., 0., ..., 0., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.],
[1., 1., 1., ..., 0., 0., 0.]]), 'y_target': tensor([0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1,
1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1,
1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0,
0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0,
0, 1, 0, 1])}